 |
TORCS
1.3.9
The Open Racing Car Simulator
|


|
|
TORCS
1.3.9
The Open Racing Car Simulator
|
|
A type of discrete action policy using a neural network for function approximation. More...
#include <ann_policy.h>
Public Member Functions | |
| ANN_Policy (int n_states, int n_actions, int n_hidden=0, real alpha=0.1, real gamma=0.8, real lambda=0.8, bool eligibility=false, bool softmax=false, real randomness=0.1, real init_eval=0.0, bool separate_actions=false) | |
| Make a new policy. More... | |
| virtual | ~ANN_Policy () |
| virtual int | SelectAction (real *s, real r, int forced_a=-1) |
| Select an action, given a vector of real numbers which represents the state. More... | |
| virtual void | Reset () |
| Reset eligibility traces. More... | |
| virtual real | getLastActionValue () |
| Return the last action value. More... | |
| virtual real * | getActionProbabilities () |
| virtual bool | useConfidenceEstimates (bool confidence, real zeta=0.01) |
| Set to use confidence estimates for action selection, with variance smoothing zeta. More... | |
 Public Member Functions inherited from DiscretePolicy Public Member Functions inherited from DiscretePolicy | |
| DiscretePolicy (int n_states, int n_actions, real alpha=0.1, real gamma=0.8, real lambda=0.8, bool softmax=false, real randomness=0.1, real init_eval=0.0) | |
| Create a new discrete policy. More... | |
| virtual | ~DiscretePolicy () |
| Kill the agent and free everything. More... | |
| virtual void | setLearningRate (real alpha) |
| Set the learning rate. More... | |
| virtual real | getTDError () |
| Get the temporal difference error of the previous action. More... | |
| virtual int | SelectAction (int s, real r, int forced_a=-1) |
| Select an action a, given state s and reward from previous action. More... | |
| virtual void | loadFile (char *f) |
| Load policy from a file. More... | |
| virtual void | saveFile (char *f) |
| Save policy to a file. More... | |
| virtual void | setQLearning () |
| Set the algorithm to QLearning mode. More... | |
| virtual void | setELearning () |
| Set the algorithm to ELearning mode. More... | |
| virtual void | setSarsa () |
| Set the algorithm to SARSA mode. More... | |
| virtual bool | useConfidenceEstimates (bool confidence, real zeta=0.01, bool confidence_eligibility=false) |
| Set to use confidence estimates for action selection, with variance smoothing zeta. More... | |
| virtual void | setForcedLearning (bool forced) |
| Set forced learning (force-feed actions) More... | |
| virtual void | setRandomness (real epsilon) |
| Set randomness for action selection. Does not affect confidence mode. More... | |
| virtual void | setGamma (real gamma) |
| Set the gamma of the sum to be maximised. More... | |
| virtual void | setPursuit (bool pursuit) |
| Use Pursuit for action selection. More... | |
| virtual void | setReplacingTraces (bool replacing) |
| Use Pursuit for action selection. More... | |
| virtual void | useSoftmax (bool softmax) |
| Set action selection to softmax. More... | |
| virtual void | setConfidenceDistribution (enum ConfidenceDistribution cd) |
| Set the distribution for direct action sampling. More... | |
| virtual void | useGibbsConfidence (bool gibbs) |
| Add Gibbs sampling for confidences. More... | |
| virtual void | useReliabilityEstimate (bool ri) |
| Use the reliability estimate method for action selection. More... | |
| virtual void | saveState (FILE *f) |
| Save the current evaluations in text format to a file. More... | |
Protected Attributes | |
| ANN * | J |
| Evaluation network. More... | |
| ANN ** | Ja |
Evaluation networks (for separate_actions case) More... | |
| real * | ps |
| Previous state vector. More... | |
| real * | JQs |
Placeholder for evaluation vector (separate_actions) More... | |
| real | J_ps_pa |
| Evaluation of last action. More... | |
| real * | delta_vector |
| Scratch vector for TD error. More... | |
| bool | eligibility |
| eligibility option More... | |
| bool | separate_actions |
| Single/separate evaluation option. More... | |
| Protected Attributes inherited from DiscretePolicy | |
| enum LearningMethod | learning_method |
| learning method to use; More... | |
| int | n_states |
| number of states More... | |
| int | n_actions |
| number of actions More... | |
| real ** | Q |
| state-action evaluation More... | |
| real ** | e |
| eligibility trace More... | |
| real * | eval |
| evaluation of current aciton More... | |
| real * | sample |
| sampling output More... | |
| real | pQ |
| previous Q More... | |
| int | ps |
| previous state More... | |
| int | pa |
| previous action More... | |
| real | r |
| reward More... | |
| real | temp |
| scratch More... | |
| real | tdError |
| temporal difference error More... | |
| bool | smax |
| softmax option More... | |
| bool | pursuit |
| pursuit option More... | |
| real ** | P |
| pursuit action probabilities More... | |
| real | gamma |
| Future discount parameter. More... | |
| real | lambda |
| Eligibility trace decay. More... | |
| real | alpha |
| learning rate More... | |
| real | expected_r |
| Expected reward. More... | |
| real | expected_V |
| Expected state return. More... | |
| int | n_samples |
| number of samples for above expected r and V More... | |
| int | min_el_state |
| min state ID to search for eligibility More... | |
| int | max_el_state |
| max state ID to search for eligibility More... | |
| bool | replacing_traces |
| Replacing instead of accumulating traces. More... | |
| bool | forced_learning |
| Force agent to take supplied action. More... | |
| bool | confidence |
| Confidence estimates option. More... | |
| bool | confidence_eligibility |
| Apply eligibility traces to confidence. More... | |
| bool | reliability_estimate |
| reliability estimates option More... | |
| enum ConfidenceDistribution | confidence_distribution |
| Distribution to use for confidence sampling. More... | |
| bool | confidence_uses_gibbs |
| Additional gibbs sampling for confidence. More... | |
| real | zeta |
| Confidence smoothing. More... | |
| real ** | vQ |
| variance estimate for Q More... | |
Additional Inherited Members | |
| Protected Member Functions inherited from DiscretePolicy | |
| int | confMax (real *Qs, real *vQs, real p=1.0) |
| Confidence-based Gibbs sampling. More... | |
| int | confSample (real *Qs, real *vQs) |
| Directly sample from action value distribution. More... | |
| int | softMax (real *Qs) |
| Softmax Gibbs sampling. More... | |
| int | eGreedy (real *Qs) |
| e-greedy sampling More... | |
| int | argMax (real *Qs) |
| Get ID of maximum action. More... | |
A type of discrete action policy using a neural network for function approximation.
Constructor arguments offer the additional option separate_actions. This is useful for the case of eligibility traces. It allows to use clearing actions traces, since it uses a separate approximator for each action, rather than a single approximator with many outputs.
The class has essentially the same interface as DiscretePolicy. A major difference is the fact that you must supply a real vector that represents the state.
Note that using Q-learning with eligibility traces in this class can result in divergence theoretically.
Definition at line 35 of file ann_policy.h.
| ANN_Policy::ANN_Policy | ( | int | n_states, |
| int | n_actions, | ||
| int | n_hidden = 0, |
||
| real | alpha = 0.1, |
||
| real | gamma = 0.8, |
||
| real | lambda = 0.8, |
||
| bool | eligibility = false, |
||
| bool | softmax = false, |
||
| real | randomness = 0.1, |
||
| real | init_eval = 0.0, |
||
| bool | separate_actions = false |
||
| ) |
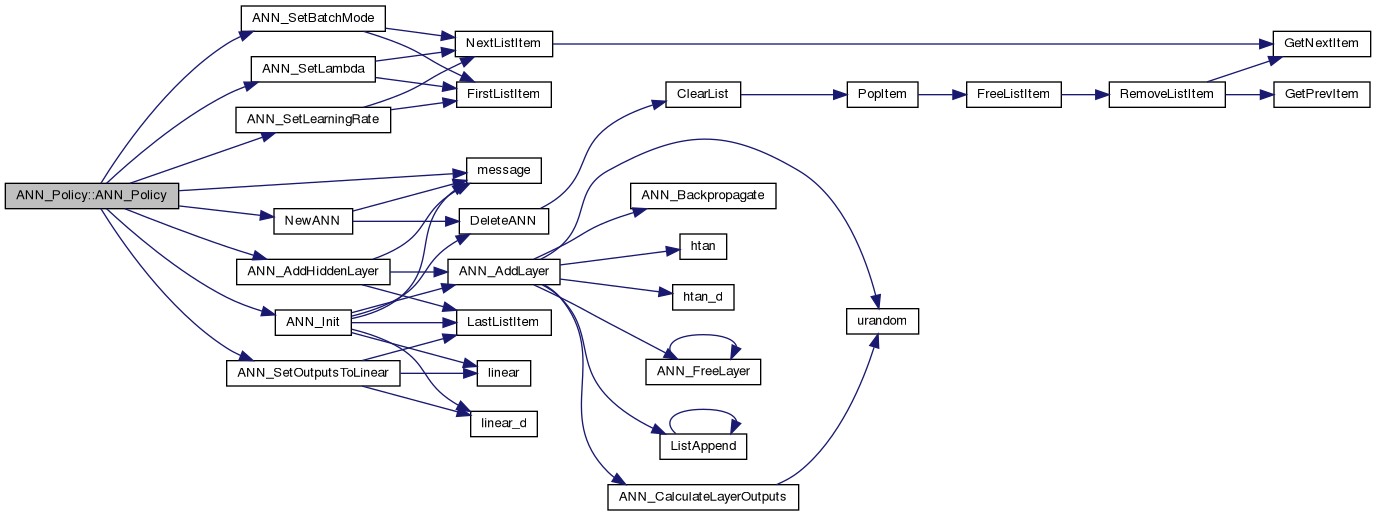
Make a new policy.
Definition at line 17 of file ann_policy.cpp.
|
virtual |
|
inlinevirtual |
Definition at line 58 of file ann_policy.h.
|
inlinevirtual |
Return the last action value.
Reimplemented from DiscretePolicy.
Definition at line 56 of file ann_policy.h.
|
virtual |
Reset eligibility traces.
Reimplemented from DiscretePolicy.
Definition at line 175 of file ann_policy.cpp.

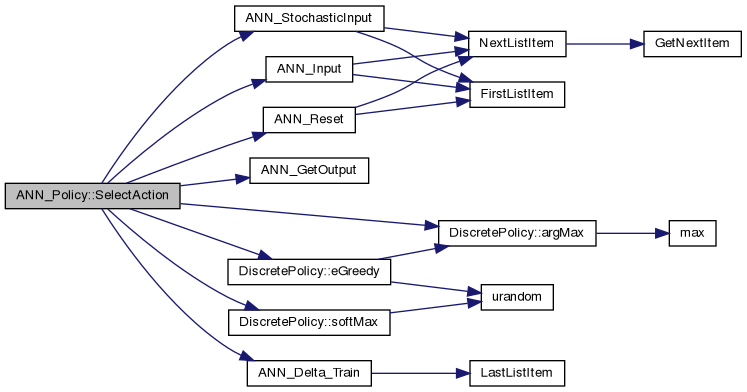
Select an action, given a vector of real numbers which represents the state.
Definition at line 75 of file ann_policy.cpp.
|
virtual |
Set to use confidence estimates for action selection, with variance smoothing zeta.
Definition at line 188 of file ann_policy.cpp.

|
protected |
Scratch vector for TD error.
Definition at line 43 of file ann_policy.h.
|
protected |
eligibility option
Definition at line 44 of file ann_policy.h.
|
protected |
Evaluation network.
Definition at line 38 of file ann_policy.h.
|
protected |
Evaluation of last action.
Definition at line 42 of file ann_policy.h.
|
protected |
Evaluation networks (for separate_actions case)
Definition at line 39 of file ann_policy.h.
|
protected |
Placeholder for evaluation vector (separate_actions)
Definition at line 41 of file ann_policy.h.
|
protected |
Previous state vector.
Definition at line 40 of file ann_policy.h.
|
protected |
Single/separate evaluation option.
Definition at line 45 of file ann_policy.h.
 1.8.14
1.8.14 